
Технология data flow на уровне процедур и процессов в симметричной ВС
"Идеальные" модели data flow (системы, управляемые потоком данных, потоковые ВС) не нашли практического воплощения. Вместе с тем, каждый разработчик, реализовавший при распараллеливании какой-то метод синхронизации частично упорядоченного множества работ, которое представляет собой любая программа или программный комплекс, утверждает, что он создал архитектуру data flow. Это традиционно увеличивает престиж разработки.
Следуя все же изначальной идее, мы под принципом data flow будем понимать такой способ синхронизации параллельного вычислительного процесса, когда отдельные составляющие его работы — программные модули, процессы, процедуры, инструкции, команды — имеют возможность распознавания и заявления о наличии всех данных для своего выполнения. Исполнительные устройства также имеют возможность распознавать работы, для которых существуют все необходимые наборы исходных данных, и выбирать эти работы для выполнения. После выполнения они влияют на состав исходных данных других работ, пополняя их. Все это способствует синхронизированному, осмысленному процессу, максимальной загрузке оборудования, автоматическому использованию всех возможностей реализуемых алгоритмов по распараллеливанию.
Принцип data flow также можно использовать на двух уровнях распараллеливания вычислительного процесса.
Рассмотрим возможность его воплощения на симметричных ВС с помощью механизма синхронизации "почтовых ящиков" (рис. 8.13).
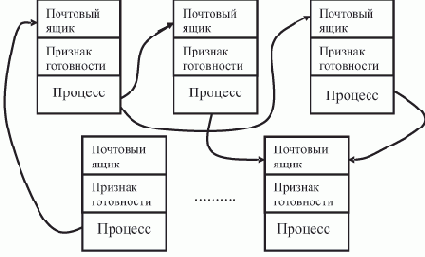
Рис. 8.13. Схема data flow с помощью "почтовых ящиков"
Процессы могут быть причудливо связаны между собой, обмениваясь через "почтовые ящики". Однако следует не допускать "зацикливания", т.е. информационный граф, соответствующий этой структуре и описывающий частичную упорядоченность работ, не должен содержать контуров.
Итак, мы уже изобразили очередь заданий "к процессору", которая может быть дополнена на основе механизма приоритетов, дополнительными средствами синхронизации с помощью семафоров — для реализации замысла пользователя при построении специализированных систем, а также возможностью "порождать" и "убивать" процессы.
Отметим также, что целесообразно совмещать принцип data flow с принципом децентрализованных ВС. Это вновь оказывается совместимым с основной идеологией семейства "Эльбрус".
